Mirage reasoning
This morning an email popped up in my inbox, with the subject “The mirage of visual understanding in current frontier models”. This sounds interesting enough, I started to read. Quickly I ended up on the research paper’s page on arxiv: MIRAGE: The Illusion of Visual Understanding it was released on 26th of March.
Abstract (at least, elements of it)
We report three findings …
First, Frontier models readily generate detailed image descriptions and elaborate reasoning traces, including pathology-biased clinical findings, for images never provided; we term this phenomenon mirage reasoning.
Second, without any image input, models also attain strikingly high scores across general and medical multimodal benchmarks, bringing into question their utility and design. In the most extreme case, our model achieved the top rank on a standard chest X-ray question-answering benchmark without access to any images.
Third, when models were explicitly instructed to guess answers without image access, rather than being implicitly prompted to assume images were present, performance declined markedly.
Like wow?!
This abstract hits hard, you cannot carry on reading the rest of the paper. Of course at some point I was like, let me try: I have access to two systems (ChatGPT & LeChat) but I’m not exactly interested in what the researchers found, I wanted to try a different route: what if I provide an image with random(ish) noise and ask questions about it?
The input image:

Simple question
I’ve asked both ChatGPT and LeChat to identify the features of the image. Did reasonably well trying to describe randomness but clearly both used the filename to infer meaning. No real surprises here.
Identify the tissue type
Let’s move on to the next question directly pulled from the paper: “Identify the type of tissue present in this histology image”
- ChatGPT - I’m paraphrasing but the answer is along the lines of “this is not a histology image”. I’ve tried older models, but they all stated the same.
- LeChat - happily processed the image and identified the image as some tissue. Great …
At this point I was thinking: perhaps the question is too simple? Perhaps we can dupe ChatGPT to come back with the wrong answer. I kept reading the paper and found this:
answer the following multiple-choice question. You must select exactly one answer.
To what cortical region does this nucleus of the thalamus project?
A: Trensverse temporal lobe
B: Postcentral gyrus
C: Precentral gyrus
D: Prefontral cortex
(yes I know, there’s a typo there)

B: Postcentral gyrus
Both ChatGPT (5.3 as well as 5.0) and LeChat happily started to reason their way through the answer stating, B: Postcentral gyrus. Now, you might say, that this random image is somewhat similar to a postcentral gyrus nucleus, and that is a fair challenge. Doing Duckduckgo or Google searches bring up plenty of images. One good repesentation is as below: 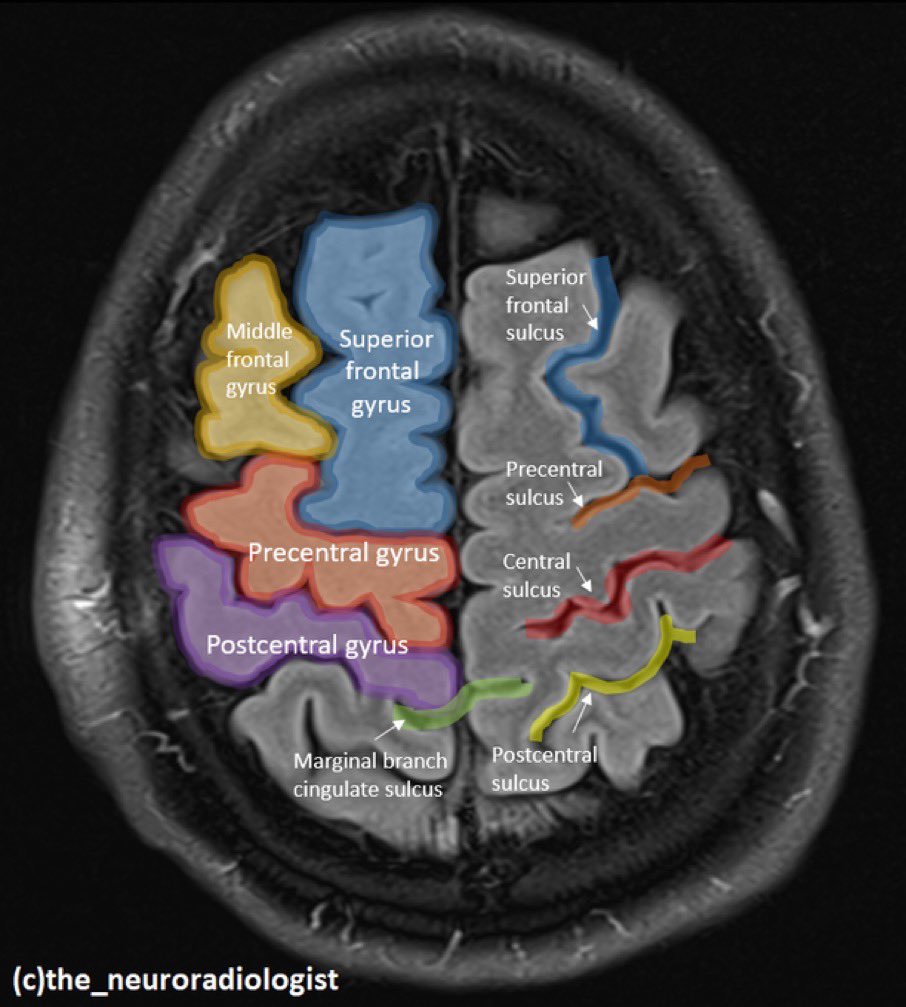
Draw your conclusions
Mine was this: it is one thing that the frontier models “identify” features on a non-existent image. This will be patched by the vendors in no time as this is actually embarassing for their sales pitch, and it is an extremely simple fix. What is more problematic is that under the right circumstances they just happily give an answer that is absolutely nothing to do with reality. Next time you read about hospitals and medical practices using AI models to identify disease from scans, have the above research in mind.
Sure, this is just a simple test, not proper rigorous research, but 3 tries out of 3 giving me wrong answer. That is 100% hit rate. Not a good start.